What it does
Data Linker lets you compare data sets of personnel records from different systems, and merge them into a single data set. This allows you to clean up your data and detect incoherent or duplicate entries.
Key features
- Select comparison rules for the datasets
- Create dynamic comparison rules on-the-fly
- Identify duplicate entries, even if first and last names are switched
- Remove all special characters for comparison such as hyphens, single quotes and spaces ( Marie-Claire -> marieclaire )
- convert all accented characters to their basic ASCII equivalent for comparison (ex. ë -> e, î -> i)
All features that change or remove characters for comparison, are used to improve detection of the same records even if spelling mistakes are made or certain characters are mistyped.
Why do I need it?
With Data Linker, you will be able to achieve your goal faster and more efficient, which will allow you to save a lot of labor costs.
Merging data correctly can be a daunting – and most importantly – an extremely expensive and time consuming task. Data Linker is a tool for system managers to help merge different data sets.
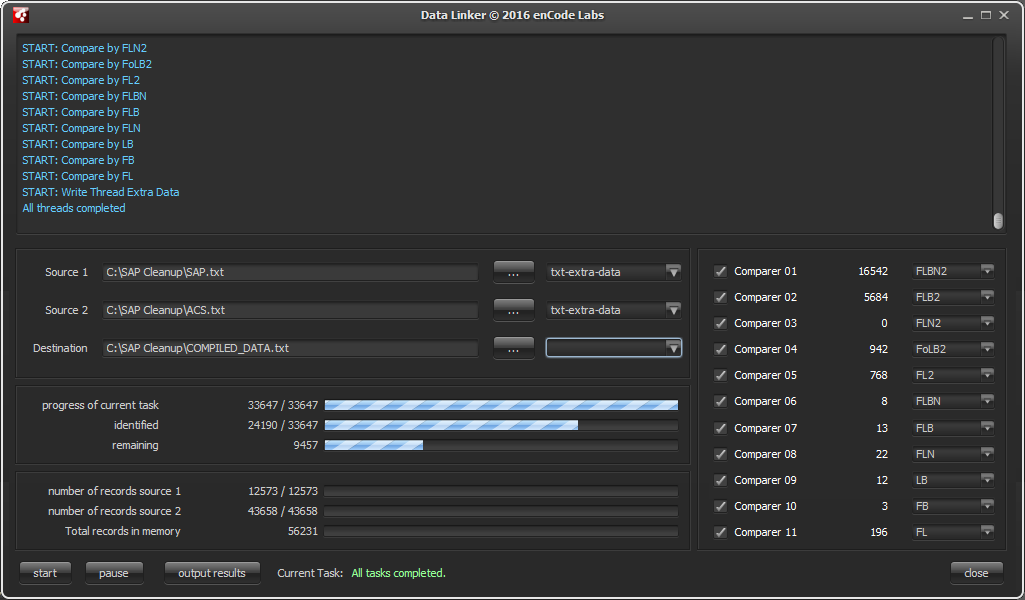
Choose your comparison rules
Choose the comparison rules you want to use for comparing your data, or define dynamic rules yourself in the application.
All data will be processed through through several comparison algorithms that you can freely configured based on your needs, and the result will be saved in a merged file. From this file you can update your systems or link the unique ID’s between both systems for setting up an automatic synchronization afterwards, and stop your system from becoming corrupted or incoherent.
Clean up your single data sets
Even your Master Data can become polluted over time. When entering data manually or from different sources, over the years you can end up with duplicate records due to different policies in time, manual encoding errors, wrong data from third parties… Whatever the reason for inconsistencies, Data Linker offers the possibility to compare your single Master Data Sets for cleanup and detect duplicate entries through its built in comparison algorithms.
Screenshot